Score every applicant. Ship the reasoning to your client.
Every candidate you submit arrives with a written evaluation, with each claim tied to a line of your client’s job description. It exports with your logo on it.
On a senior search, they’re buying your judgment.
On a senior search, the client is paying for your judgment. The submittal is where they see it.
Every firm on the assignment sends the same thing: a resume, and a paragraph someone typed from memory. It’s also the first thing that gets short when you’re behind.
What recruiters told us.
Anonymous research conversations, not endorsements.
“I went through 300 resumes and only passed 3 along.”
“I spent 3.5 hours in bed last night rejecting candidates.”
None of that reading is billable. It happens before the work the client pays for even starts.
Every claim tied to a line of their job description.
A written evaluation on every candidate you put forward. Each claim is tied to a line of the job description your client wrote, so they can check it against the brief.
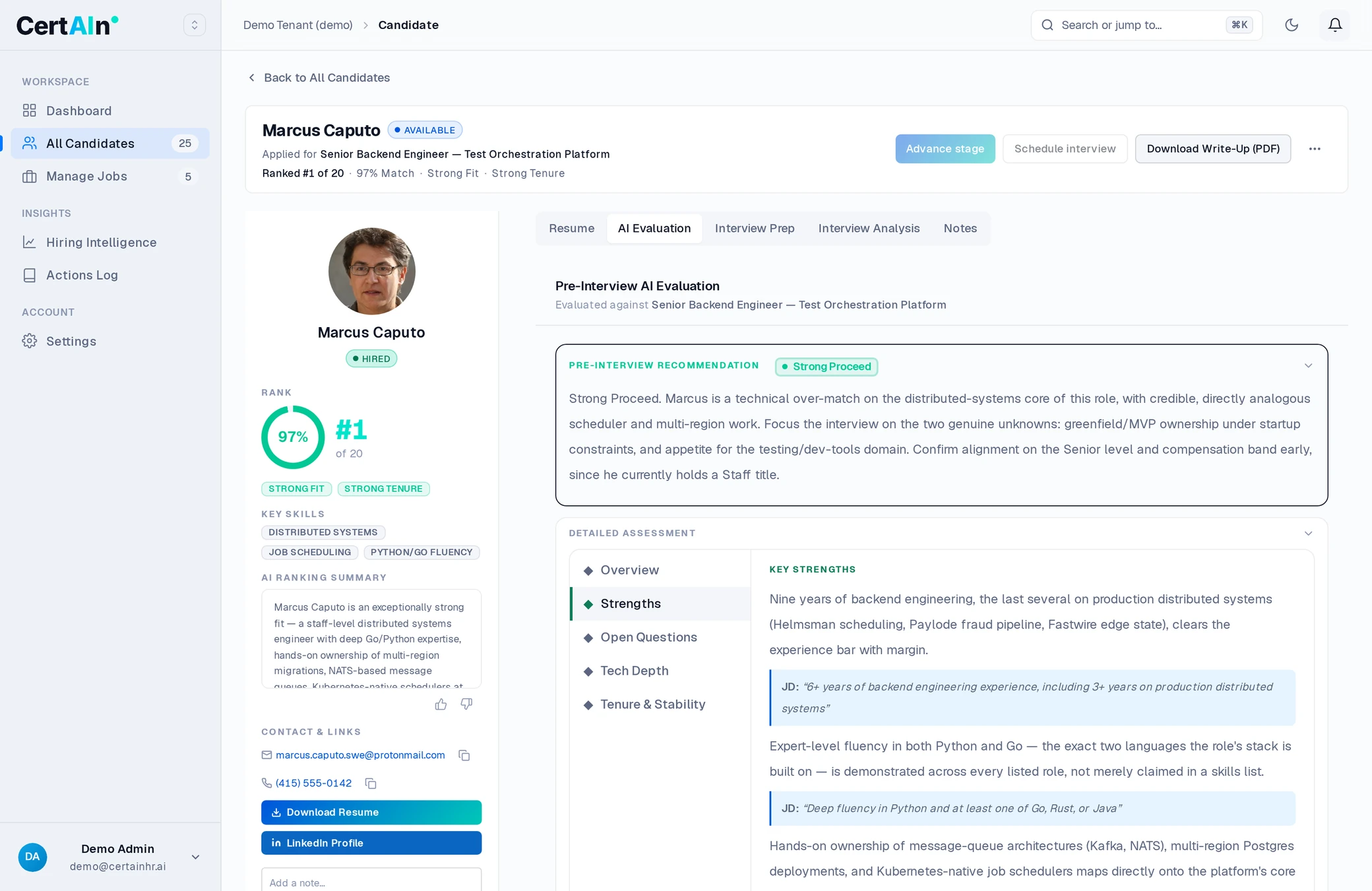
The evaluation a consultant sees. It exports as the client document. Demo workspace: the candidate and role are fictional.
It’s a written argument, not a number, and it exports with your logo on it.
The consultant decides. Always.
CertAIn never rejects, advances, schedules, or messages a candidate. There is no setting that lets it. Every output is a recommendation. A person makes the call.